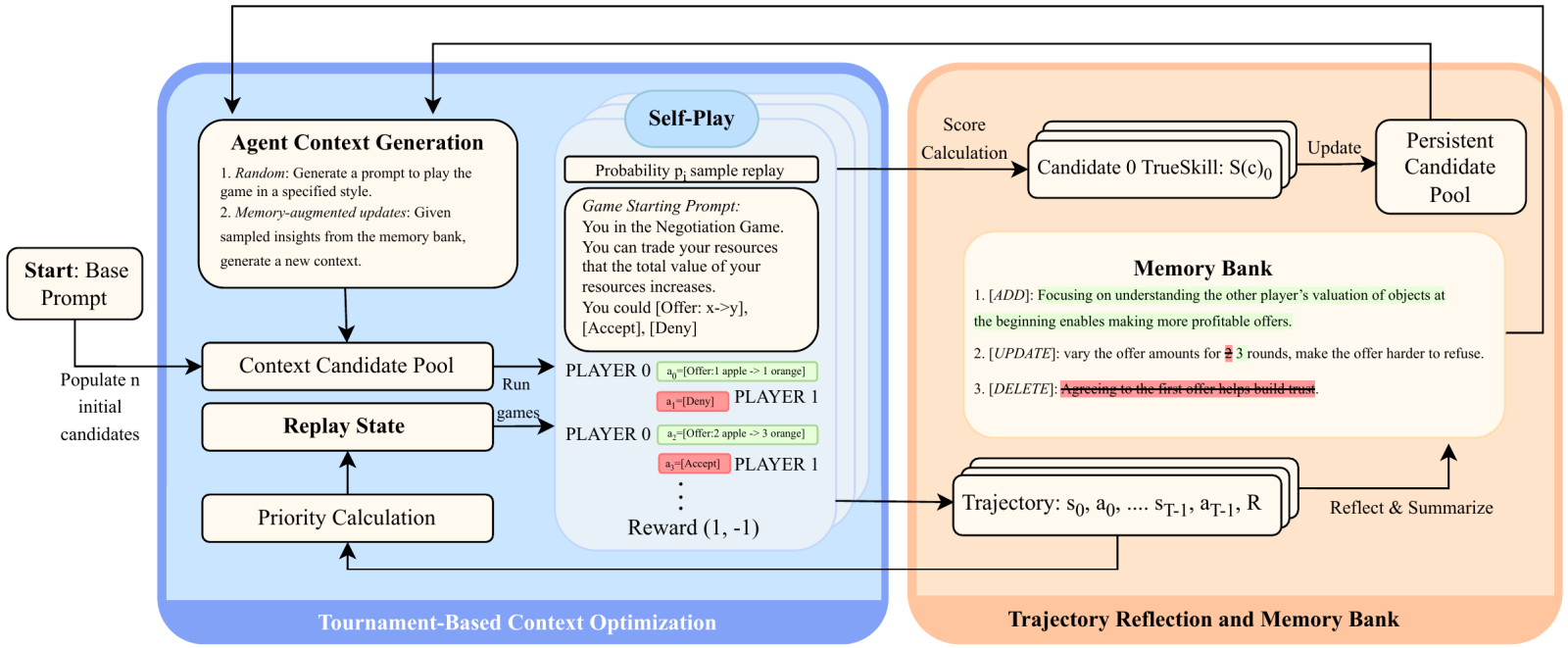
Evaluating LLMs in competitive multi-agent settings is unreliable: small early deviations compound across turns, and inconsistent prompting produces wildly different outcomes, making tournament rankings unstable and hard to trust.
We address this with MEMO, a self-play framework that stabilizes and improves LLM agent performance by optimizing inference-time context through two coupled mechanisms. A persistent memory bank retains structured insights from past self-play trajectories and injects them as priors in future rounds, while an exploration module searches for more effective prompt policies. MEMO reduces run-to-run variance and raises win rates, offering a principled foundation for reliable LLM evaluation in multi-agent game settings.
Authors: Yunfei Xie, Kevin Wang, Bobby Cheng, Jianzhu Yao, Zhizhou Sha, Alexander Duffy, Yihan Xi, Hongyuan Mei, Cheston Tan, Chen Wei, Pramod Viswanath, Zhangyang Wang
Link to paper and Twitter thread. All code for our experiments can be found here.